
目次
インストール
Biopythonは塩基配列やタンパクの配列を読み込み簡単に編集できるようにするためのパッケージです(他にも色々できます)。
公式ページ(https://biopython.org/)
今回はインストールと簡単な処理を行ってみます。
まずはpipコマンドを使用してインストールします。
bio@bio:$python3 -m pip install biopython
Defaulting to user installation because normal site-packages is not writeable
Collecting Biopython
Downloading biopython-1.79-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (2.7 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.7/2.7 MB 21.9 MB/s eta 0:00:00
Requirement already satisfied: numpy in ./.local/lib/python3.10/site-packages (from Biopython) (1.22.3)
Installing collected packages: Biopython
Successfully installed Biopython-1.79インストールの終了です。
シーケンスデータの作成と編集(相補鎖:complement、逆相補鎖:reverse_complement)
インストールが無事にできたらjupyter-labから使用してみます。もちろん適当なIDEでもいいです。
bio@bio:~$jupyter-lab起動したら以下の画像を参考にサンプルを実行してみましょう
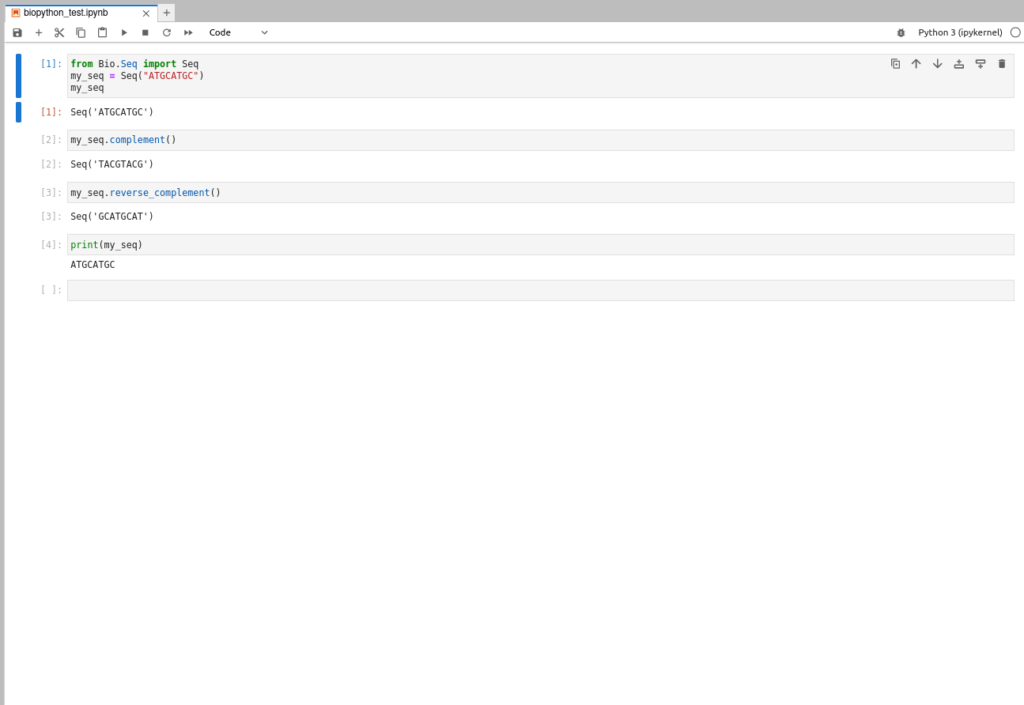
上から説明していきます。
今回必要なSeqモジュールをインポートします。
my_seq という適当な名前の箱を作り、中身を Seq(“練習用の適当な配列”) で作成します。
my_seq で実行すると中身が表示されます。
また my_seq.処理するコマンド() で中身を相補鎖にしたり、逆相補鎖に変更できます。
こんな感じで、自分でいちからプログラムを組まなくても一般的に使用される処理であれば一行で簡単に処理できます。
Biopythonは多機能なので、チュートリアル(http://biopython.org/DIST/docs/tutorial/Tutorial.html)を参考にしながら使用してください。
塩基のカウント(count)
特定の塩基をカウントするにはcountを使用します。
ちなみにcountは小文字と大文字を区別してカウントします。取り扱うファイルによっては小文字になっていたり、特殊塩基が小文字や大文字になっていたりしますので、そういったケースも考慮してcount関数を使用する必要があります。

コメント